We propose MM-REACT, a system paradigm that integrates ChatGPT with a pool of vision experts to achieve multimodal reasoning and action. In this paper, we define and explore a comprehensive list of advanced vision tasks that are intriguing to solve, but may exceed the capabilities of existing vision and vision-language models. To achieve such advanced visual intelligence, MM-REACT introduces a textual prompt design that can represent text descriptions, textualized spatial coordinates, and dense visual signals such as images and videos represented as aligned file names. MM-REACT’s prompt design allows language models to accept, associate, and process multimodal information, thereby facilitating the synergetic combination of ChatGPT and various vision experts. Zero-shot experiments demonstrate MM-REACT’s effectiveness in addressing the specified capabilities of interests and its wide application in different scenarios that require complicated visual understanding. Furthermore, we discuss and compare MM-REACT’s system paradigm with an alternative approach that extends language models for multimodal scenarios through joint finetuning.
MM-ReAct is a system paradigm that composes numerous vision experts with ChatGPT for multimodal reasoning and action.

Flowchart of MM-REACT to enable image understanding with ChatGPT.
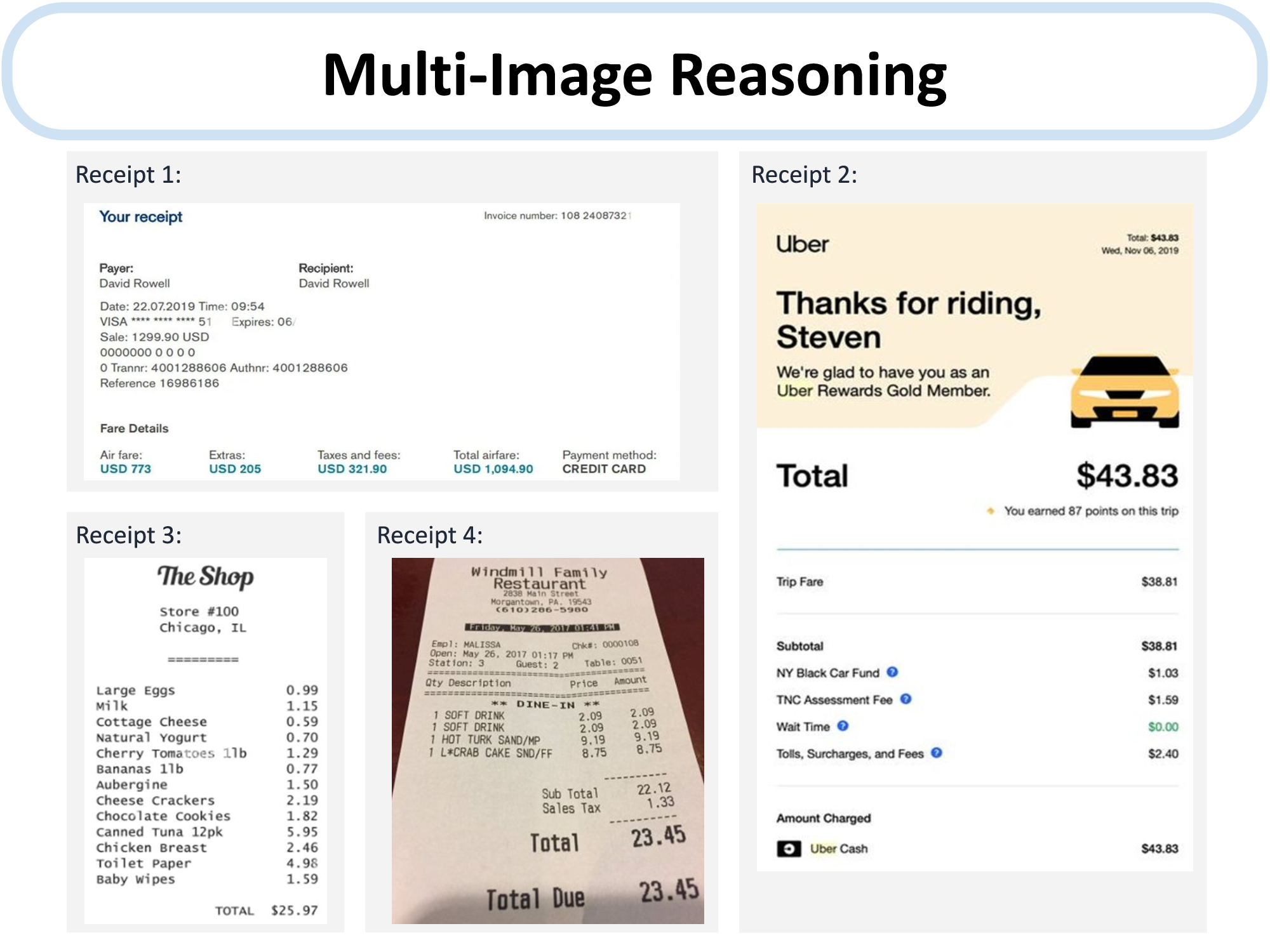
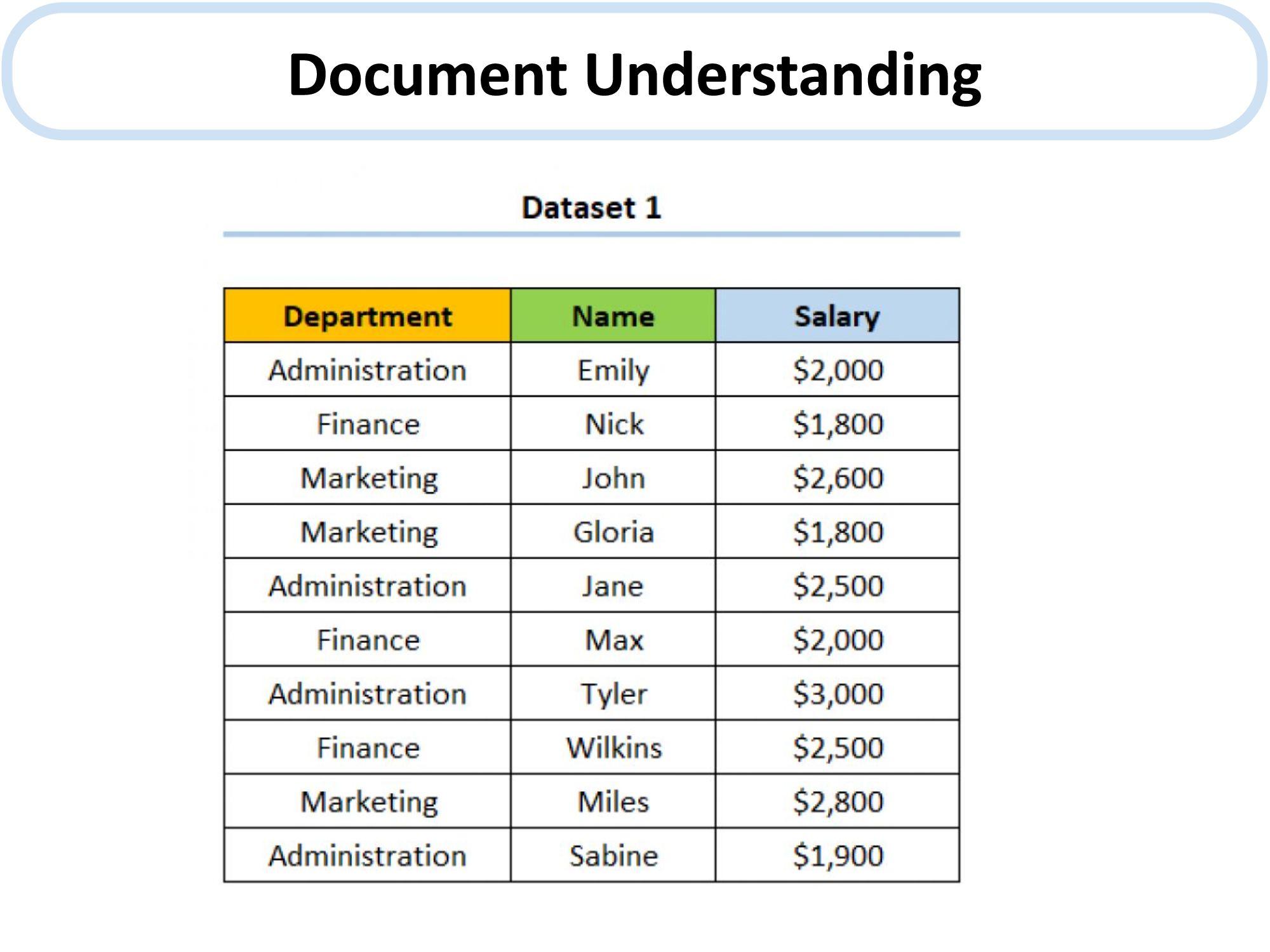
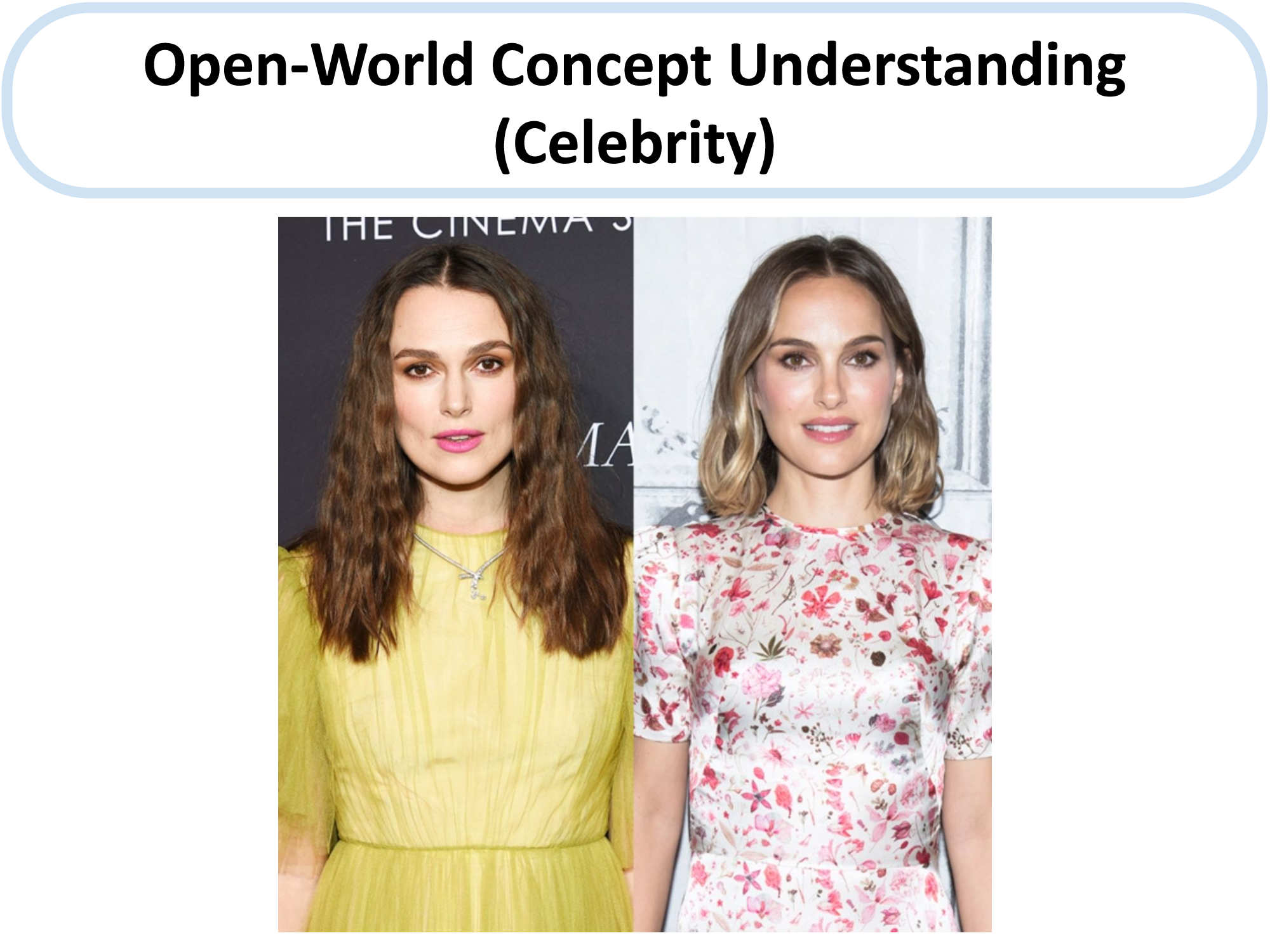
We provide an examples of MM-REACT’s full execution flow blow. More examples can be found in our paper.

An example of MM-REACT’s full execution flow.






@article{yang2023mmreact,
author = {Zhengyuan Yang* and Linjie Li* and Jianfeng Wang* and Kevin Lin* and Ehsan Azarnasab* and Faisal Ahmed* and Zicheng Liu and Ce Liu and Michael Zeng and Lijuan Wang^},
title = {MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action},
publisher = {arXiv},
year = {2023},
}
We would like to express our gratitude to Jianfeng Gao for his valuable suggestions, as well as to Jianwei Yang for generously providing the image editing tool utilizing the X-Decoder framework.
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
